您现在的位置是:生活百科网 > 生活百科 >
pyp(pyp是什么意思)
2022-05-09 16:40生活百科 人已围观
简介数据分析能力是企业全面数字化经营的核心。整理|苏霍伊4月27日,中国科技产业智库「甲子光年」线上举办了2022年「甲子引力X」数字经济高峰论坛。本次论坛以“产业科创新坐标”为...
数据分析能力是企业全面数字化经营的核心。
整理 | 苏霍伊
4月27日,中国科技产业智库「甲子光年」线上举办了2022年「甲子引力X」数字经济高峰论坛。本次论坛以“产业科创新坐标”为主题,试图在有限性、无限性和不确定性中寻找数字经济的“坐标系”。
在下午的“数字生产力”专场中,StarRocks联合创始人&COO叶谦带来了《全新数据分析能力赋能数字生产力全面升级》的主题演讲。他认为,数据分析是企业数字生产力的核心,新一代极速全场景MPP数据库StarRocks的价值便是释放数字生产力。
以下为叶谦的演讲实录:
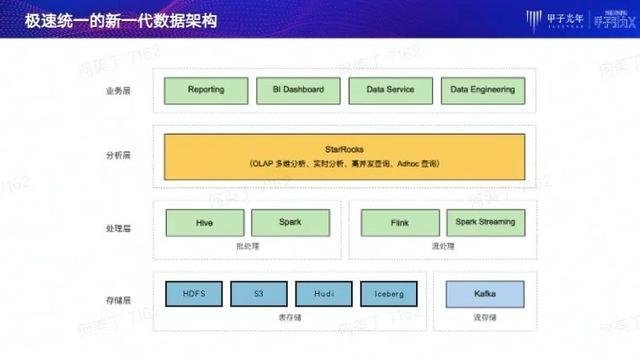
StarRocks 成立两年多来倾力打造世界顶级的新一代极速全场景 MPP 数据库,就是希望能够帮助企业建立“极速统一”的数据分析新范式,从而实现企业全面数字化经营。
StarRocks高度注重技术驱动,公司研发人员比例达到70%。StarRocks 采用Open Core的模式,于去年9月份开放源代码之后,在Github上的星数已超过2400个。当前已经有超过110家估值或市值在10亿美金以上的中大型用户,在生产环境中使用StarRocks,这些用户来自于各行各业。
1.极速统一的新一代数据架构

其次,StarRocks可以给业务带来全新的业务洞察实时性。数据实时导入StarRocks可实现即时可见。不仅如此,StarRocks还支持数据更新操作,数据在实时导入和更新的时候,查询的速度依然能够表示在秒级。对于业务数据更新需求大的用户来说是非常友好的特性;
第三,StarRocks支持数千人同时进行数据分析工作。对那些需要数据驱动一线运营的公司来说,在部分场景StarRocks可以到达1万以上并发量,并且还可以控制TP99在1秒以内。
第四,由于能够在多种场景下实现极速查询的目标,这使得StarRocks可以灵活使用各种数据建模的方式,数据工程师和数据分析师可以使用大宽表,也可以使用星型模型或者雪花模型。不再依赖于预计算或者大宽表去提速,业务交互的速度可以得到极大改善。不少用户在使用StarRocks之后,业务速度从周加快到小时,甚至是分钟级别,生产力得到极大提升。
基于StarRocks,用户可以打造一个全新的极速统一的数据架构。在这个数据架构里,整个OLAP分析层可以统一到StarRocks中,它不仅能实现OLAP多维分析、实时数据分析、高并发查询以及探索式分析等多场景下的极速分析效果,还可以极大减少不同数据分析组件的建设和维护成本。应用新一代数据架构之后,企业可以在更多场景使用星型模型、雪花模型来替代原有的预计算和大宽表模式,免除了数据链路建设复杂性,并且增强了数据分析的灵活性。
作为一个成熟的企业级数据库产品,StarRocks不仅产品安全稳定、服务可靠,生态也很完善。
首先,StarRocks是一个完整、独立的系统,整个系统无单点,任何节点宕机均不影响系统的可用性。StarRocks具有很好的弹性伸缩能力,可以实现在大数据规模下在线扩容,相对其他产品运维成本更低。更值得一提的是StarRocks的稳定性,经历过“双十一”这样极端业务流量的检验。
其次,StarRocks相关生态非常完善。产品支持标准SQL语法,兼容MySQL协议,支持各类主流的BI系统,包括Tableau 、永洪等,支持各类主流数据源的接入,包括各种TB数据库、HDFS、S3等。
StarRocks周边运维工具也比较完善,不仅有自研的运维工具,还可以很方便对接各类流行的开源工具。
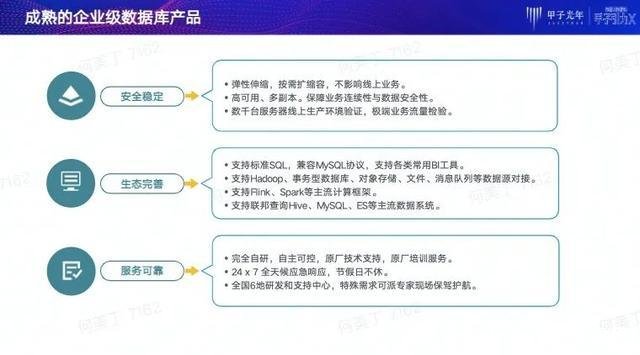
最后,StarRocks提供了可靠的企业级服务保证。StarRocks核心技术完全自研可控,在出现问题时,可以为企业客户提供全天候不休的原厂技术支持。我们在全国六地都有技术支持中心,包括北京、上海、杭州、广州、成都、西安等城市。在企业有特殊需求的时间点,比如说“双十一”或者年度大促,可以安排原厂的工程师进行现场支持。
目前,已经有数百家客户在线上生产环境部署和使用了StarRocks。其中估值或市值在10亿美金以上的大客户超过110家,还有像Airbnb 这样市值超过千亿美金的美国企业。这些客户包含了互联网金融、物流、制造等各行各业的头部企业,每个客户从开始测试到生产环境上线StarRocks平均周期约为两个月,这对于软件来说是非常短的时间周期。
2.三大核心能力支持企业典型业务场景
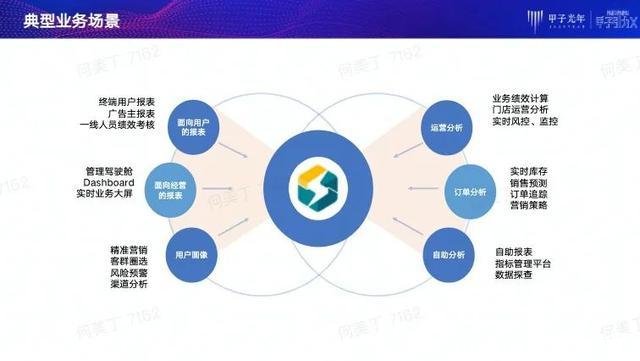
大家可能会非常感兴趣,这些用户主要将StarRocks应用在哪些场景呢?
首先是面向用户的报表。这类报表一般是给终端用户看的数据产品,其特点是数据时效性很高、同时使用人很多,因此并发查询量会比较高。由于每个人只看自己的数据,不会看别人的数据,所以每次查询高广泛的数据量是十分有限的。这种类型的数据报表对于系统并发能力、数据实时导入要求很高,没有办法使用预计算系统来进行支持。
第二是面向经营的报表。这类报表的主要受众是管理层和业务方,其特点是对聚合计算能力要求比较高,需要查询速度非常快,因为老板都不喜欢等待。而且,这种类型的报表一般需求会比较多,对于需求完成的时间点要求严格,所以如果以基于预计算或者大宽表的方式来完成此类报表,过程对操作人员而言会十分“痛苦”。
第三是用户画像。用户画像是非常普遍的场景,基本任何初期的运营场景都会遇到。它涉及到很多人群相关的操作,包括标签的圈选、根据个人ID来查询标签等。在这个场景下的StarRocks Bitmap数据类型会大有用武之地。
第五是订单分析。这类分析的主要特点是数据为流式导入,并且订单往往有分析的需求。例如,订单的状态会随着时间的推移发生变化,这要求底层数据分析系统能够支持实时数据的分析和更新,这两点都是StarRocks的强项。
第六是自助分析。这里包括自助报表和指标管理平台、数据探查等。此类场景普遍要求对接上层BI系统,这类分析所产生的SQL语句较为复杂,并且通常涉及多张数据表,这就要求数据分析系统能够处理复杂的SQL。不仅要支持复杂的SQL语法,还需快速返回,给分析人员良好的交互式体验。
StarRocks有哪些核心能力支持上述场景呢?
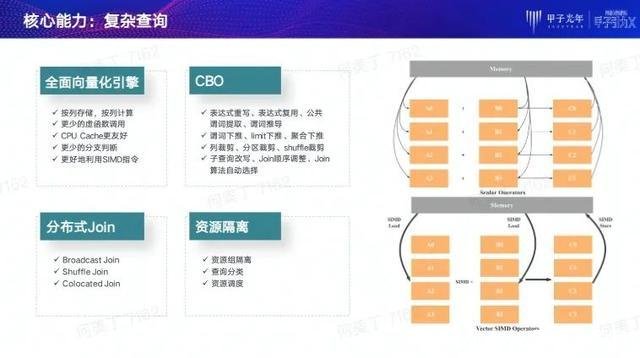
首先是对复杂查询的处理能力。我们为此实现了以下关键点:
全面向量化执行引擎。StarRocks通过实现全面向量化执行引擎,充分发挥了CPU的处理能力。经过标准测试集的验证,StarRocks的全面向量化引擎可以将算子执行性能提高3到10倍。
CBO(Cost-Based Optimizer)。在多表关联的场域场景下,仅仅靠优秀的查询执行引擎没有办法获得极致的执行性能。而通过StarRocks全新自研的优化器,可以实现多种优化手段,帮助向量化引擎发挥更加极致的特性。
分布式Join。StarRocks可以实现多种类型的分布式Join操作,适合于包括大表和小表的Broadcast Join、大表和中表的Shuffle Join、大表和大表的Colocate Join。
资源隔离。对于数据分析系统用户,常常会担心单条查询过大,将整个集群资源耗尽,从而导致其他查询没有办法执行。解决这个问题的关键就在于一个优秀的资源隔离机制。
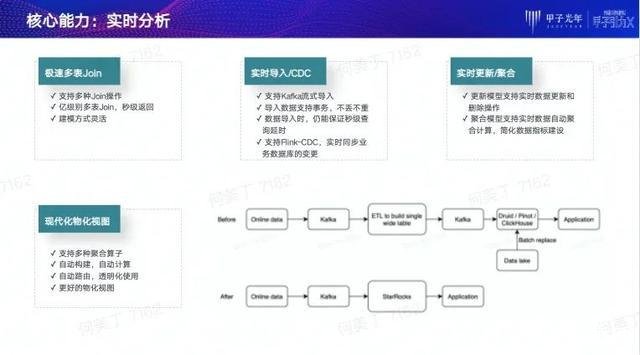
第二项核心能力是实时数据分析能力。我们为此实现了以下关键点:
极速多表Join。StarRocks的多表Join性能在行业里处于领导地位。
实时数据导入。StarRocks可以支持从Kafka实时导入数据,并且导入数据支持事务,可以做到不丢不重。支持Flink - CDC,可以直接从OLTP数据库直接对接数据。
实时更新能力。StarRocks具有独特的更新模型。更新模型可以很好支持数据的实时更新,并且能够保证数据在实时更新时查询的低延时。这个能力目前在同类型产品中非常独特。
现代化物化视图。StarRocks可以支持多种聚合算子,在数据实时导入物化视图过程中自动构建、自动计算,并且物化视图在使用时对于用户来说是透明的。
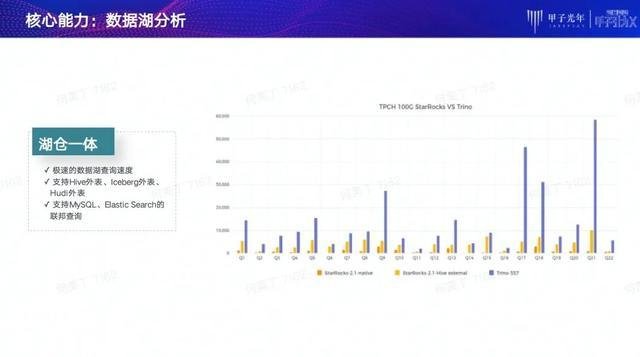
第三项核心能力是数据湖整合分析能力。
这项分析能力可以让用户像查询StarRocks自有数据般,极速查询数据湖里的数据,不再需要数据传输和迁移的过程。这项工作由StarRocks社区和阿里云一起协作开发完成。目前,我们已经支持查询Hive、Hudi和Icebreg这样的数据湖,并且还支持像MySQL、Elastic Search等外表联邦查询。
如上图所示,在使用相同外表的方式进行查询时,StarRocks外表查询性能已经要远远高于Trino的性能;如果将数据进一步导入StarRocks,查询会变得更加快,在某些特定的查询和场景上可达Trino的几十倍。
基于独特的产品能力,StarRocks为客户极大提升了数字生产力,帮助客户将查询的等待时间缩短到1秒之内,并将客户、数据业务需求的开发周期缩短约90%,还可以帮助客户降低数据分析系统建设成本,提高数据系统分析性的稳定性。
3.众安保险、携程:全新实时分析能力开启数字化经营新局面
接下来,我将以两个案例来讲解StarRocks是如何帮助企业提高数字生产力的。

集智平台涵盖了可视化分析、交互式分析、多维透视分析、实时数据分析等多种不同种类的分析。在原有解决方案里,众安集智平台遇到了几个问题:一,使用了ClickHouse作为查询引擎,ClickHouse在支持平台的过程中,平台在高并发场景下平均响应时间会变长;二,多表关联查询性能欠佳,因此集智平台只能使用大宽表来做分析;三,对外部系统有依赖、运维成本高和缺少自动Resharding机制,导致其在做横向扩容时很困难;此外,有原有系统对更新和删除支持能力弱等问题。
在使用StarRocks解决方案之后,以上问题都得到了很好的解决。首先StarRocks能够支持高并发查询,在一些特定场景查询并发数可以高达1万以上,多表关联的查询性能优异,可以帮助开发人员灵活使用各类数据分析模型。
另外StarRocks不依赖外部系统,易于运维,可以降低运维成本。在使用StarRocks之后,集智平台的报表看板打开速度从10秒下降到3秒,极大优化了用户的体验。由于StarRocks能够很好支持数据更新和删除操作,所以极大降低了业务需求的开发成本,极大地提升产出效率。
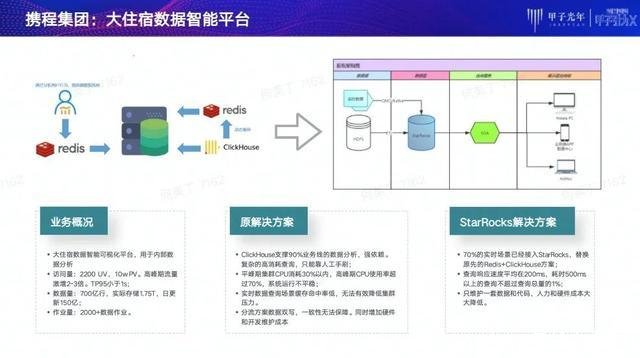
第二个案例来自于携程大数据智能平台。此平台主要用于携程住宿内部进行数据管理和数据分析,平台访问量大概每天UV在2200左右,峰值的总PV约10万左右,高峰期流量会有比较大激增。这和携程的业务量有关,只要节假日,平台整个流量会有较大的增幅。目前,数据量大概有700亿行,实际存储有1.75T,每天有150亿的更新。
在原有系统中,携程选用ClickHouse支撑90%业务线数据分析。但由于ClickHouse在稳定性和高并发方面的问题,导致了携程需同步使用Redis作为缓存。这引发了其他问题,比如双流双写的方案无法保证数据一致性,同时也增加硬件和开发的维护成本等。
在使用StarRocks之后,原先的Redis+ClickHouse的方案被完全替代。新方案让整个平台查询响应平均在200毫秒左右,耗时超过500毫秒查询不超过查询总量的1%。更为重要的是,由于简化了整体的数据架构,使得整个系统维护的人力和硬件成本大大降低,开发的复杂度也大大下降。
下一篇:三文鱼是海鲜吗(三文鱼是海鲜吗)
相关文章
- 2023北京本科普通批985院校投档线:清华685、北大683、武大653分
- 广东考生上华南理工大学难吗?
- 上海这3所大学2023考研复试分数线公布
- 最大相差178分!南京理工大学投档线集锦!最高681分,最低503分
- 2023湖北物理类投档线:武科大573、湖大563、江大536、武体506分
- 多少分能上南大?2023南京大学在苏录取数据盘点,这些途径可以走
- 2023山东高考,省内分数线最高的十所大学
- 国防科技大学录取分数线是多少?附国防科技大学毕业去向
- 郑州大学多少分能考上?2024才可以录取?附最低分数线
- 北京航空航天大学2023年录取分数线及省排名
- 哈尔滨工业大学(威海)、(深圳)校区2023年录取分数情况
- 2023广东本科投档线出炉!请看中大/华工/深大/华师/暨大等分数线
随机图文

懋的拼音(懋的拼音读什么)
懋的拼音奥运冠军施廷懋的“懋”字和谌利军的“谌”怎么读?我看到时不会读...
金融类专业选择:职业方向与前景分析
高中邦教育认为在职业选择上,没有绝对的好与坏,关键在于找到适合自己的道...
艾滋病症状初期征兆,艾滋病症状初期征兆红斑图片
大家好,今天给各位分享艾滋病症状初期征兆的一些知识,其中也会对艾滋病症...
豆子_豆子煮水喝有什么功效
豆子的种类有哪些根据荚果特性,可分为硬荚豌豆和软荚豌豆,软荚豌豆又进一...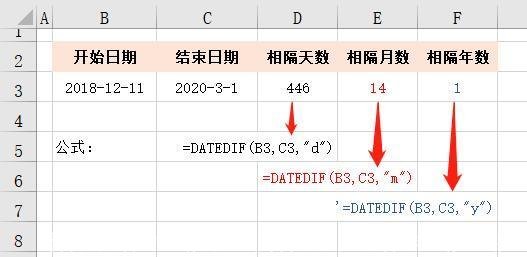
计算几天后的日期函数(计算多少天之后的日期公式)
大家好,今天来为大家解答关于计算几天后的日期函数这个问题的知识,还有对...
霁字用于人名寓意(霁字用于人名寓意玄幻小说排行榜)
求一个简单又有寓意的女宝宝名字,姓“朱”。个人觉得沫,芮,昕,然,彦,...
郑州小商品批发市场(郑州万博小商品批发市场)
在市场东门,几位工作人员正在逐一检查进出者的身份,商户进出市场需要佩带...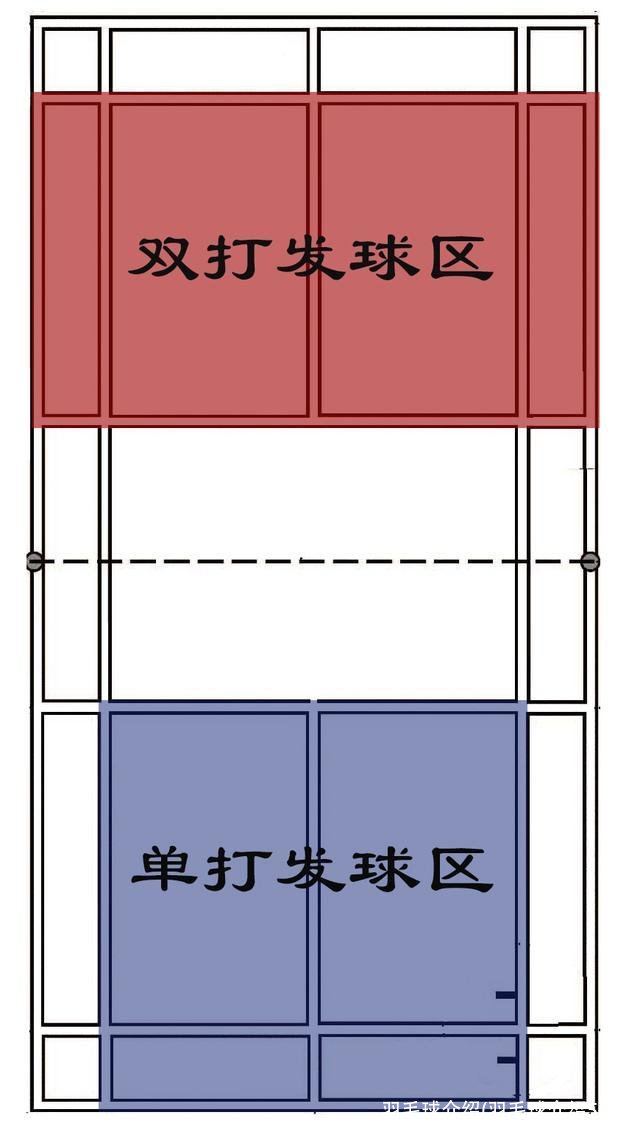
羽毛球介绍(羽毛球介绍50字)
了解羽毛球场地尺寸的目的:你所处的位置到网前或者是底线的距离,以及你采...